MapReduce
Why MapReduce is needed
In practical business scenarios we often need to get the corresponding properties from different rpc services to assemble complex objects.
For example, to query product details.
- Product Service - Query Product Attributes
- Inventory service - query inventory properties
- Price service - query price attributes
- Marketing service - query marketing attributes
If it is a serial call, the response time will increase linearly with the number of rpc calls, so we will generally change serial to parallel to optimize performance.
The simple scenario of using waitGroup can also meet the needs, but what if we need to check the data returned by the rpc call, process the data to convert, and aggregate the data? The go-zero authors have implemented an in-process data batching mapReduce concurrency tool class based on the mapReduce architecture.
Design Ideas
Let's try to put ourselves into the role of the author to sort out the possible business scenarios of concurrent tools.
- Query commodity details: support concurrent calls to multiple services to combine product attributes, and support call errors can be ended immediately.
- Automatic recommendation of user card coupons on product details page: support concurrently checking card coupons, check failure automatically rejects and returns all card coupons.
The above is actually processing the input data and finally outputting the cleaned data. There is a very classic asynchronous pattern for data processing: the producer-consumer pattern. So we can abstract the life cycle of data batch processing, which can be roughly divided into three phases.
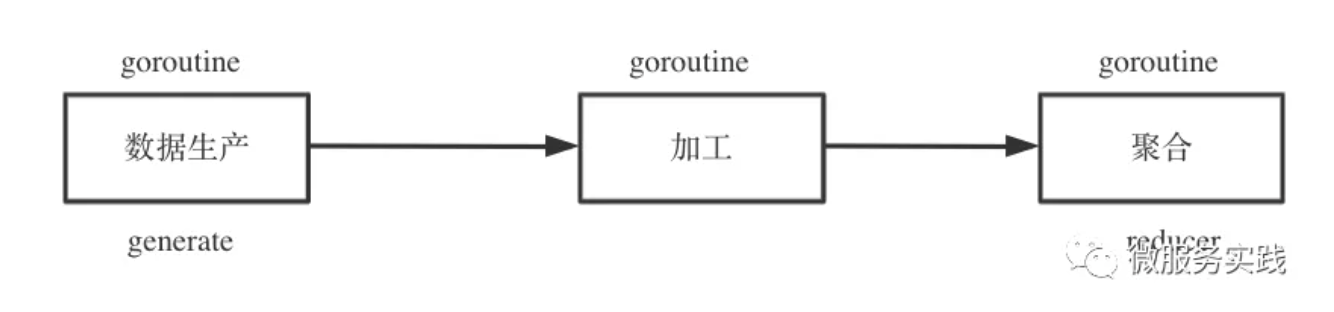
- Data production generate
- data processing mapper
- data aggregation reducer
Data production is an indispensable stage, data processing and data aggregation are optional stages, data production and processing support concurrent calls, data aggregation is basically a pure memory operation single concurrent process can be.
Since different stages of data processing are performed by different goroutines, it is natural to consider using channel to achieve communication between goroutines.
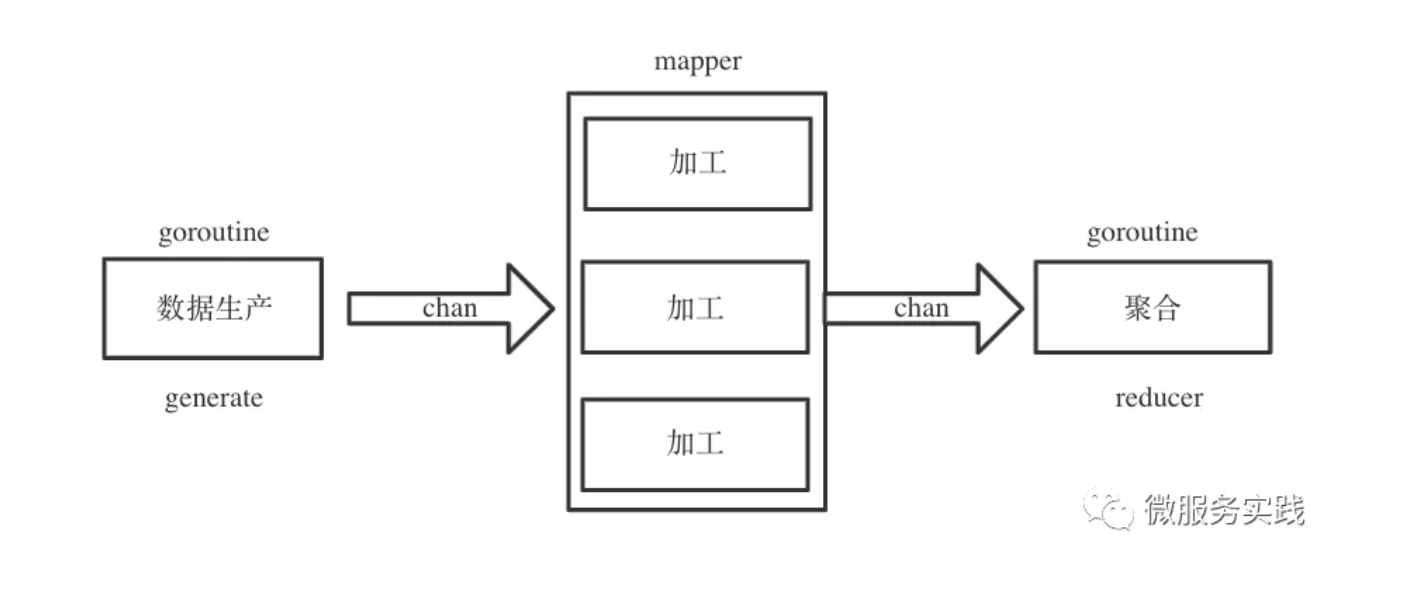
How can I terminate the process at any time?
It's very simple, just listen to a global end channel in the goroutine.
go-zero code implementation
core/mr/mapreduce.go
Pre-requisite Knowledge - Channel Basic Usage
Since the MapReduce source code makes extensive use of channels for communication, a general reference to basic channel usage is as follows.
Remember to close the channel after writing
ch := make(chan interface{})
// You need to actively close the channel after writing
defer func() {
close(ch)
}()
go func() {
// v,ok mode Read channel
for {
v, ok := <-ch
if !ok {
return
}
t.Log(v)
}
for i := range ch {
t.Log(i)
}
for range ch {
}
}()
for i := 0; i < 10; i++ {
ch <- i
time.Sleep(time.Second)
}
Closed channels still support reads
Restricted channel read and write permissions
func readChan(rch <-chan interface{}) {
for i := range rch {
log.Println(i)
}
}
func writeChan(wch chan<- interface{}) {
wch <- 1
}
Interface definitions
Let's start with the three most core function definitions.
- Data production
- Data processing
- Data aggregation
GenerateFunc func(source chan<- interface{})
MapperFunc func(item interface{}, writer Writer, cancel func(error))
ReducerFunc func(pipe <-chan interface{}, writer Writer, cancel func(error))
User-oriented method definition
The use of methods can be viewed in the official documentation, here not to repeat
There are more user-oriented methods, and the methods are divided into two main categories.
- No return
- The execution process terminates immediately when an error occurs
- The execution process does not focus on errors
- With return value
- Manually write to source, manually read aggregated data channel
- Write manually to source, read aggregated data automatically channel
- External incoming source, read aggregated data automatically channel
func Finish(fns ...func() error) error
func FinishVoid(fns ...func())
func Map(generate GenerateFunc, mapper MapFunc, opts ...Option)
func MapVoid(generate GenerateFunc, mapper VoidMapFunc, opts ...Option)
func MapReduceVoid(generate GenerateFunc, mapper MapperFunc, reducer VoidReducerFunc, opts ...Option)
func MapReduce(generate GenerateFunc, mapper MapperFunc, reducer ReducerFunc, opts ...Option) (interface{}, error)
func MapReduceWithSource(source <-chan interface{}, mapper MapperFunc, reducer ReducerFunc,
opts ...Option) (interface{}, error)
The core methods are MapReduceWithSource and Map, and all other methods call them internally. Once you figure out the MapReduceWithSource method, it's not a big deal to call Map.
MapReduceWithSource source code implementation
It's all in this diagram
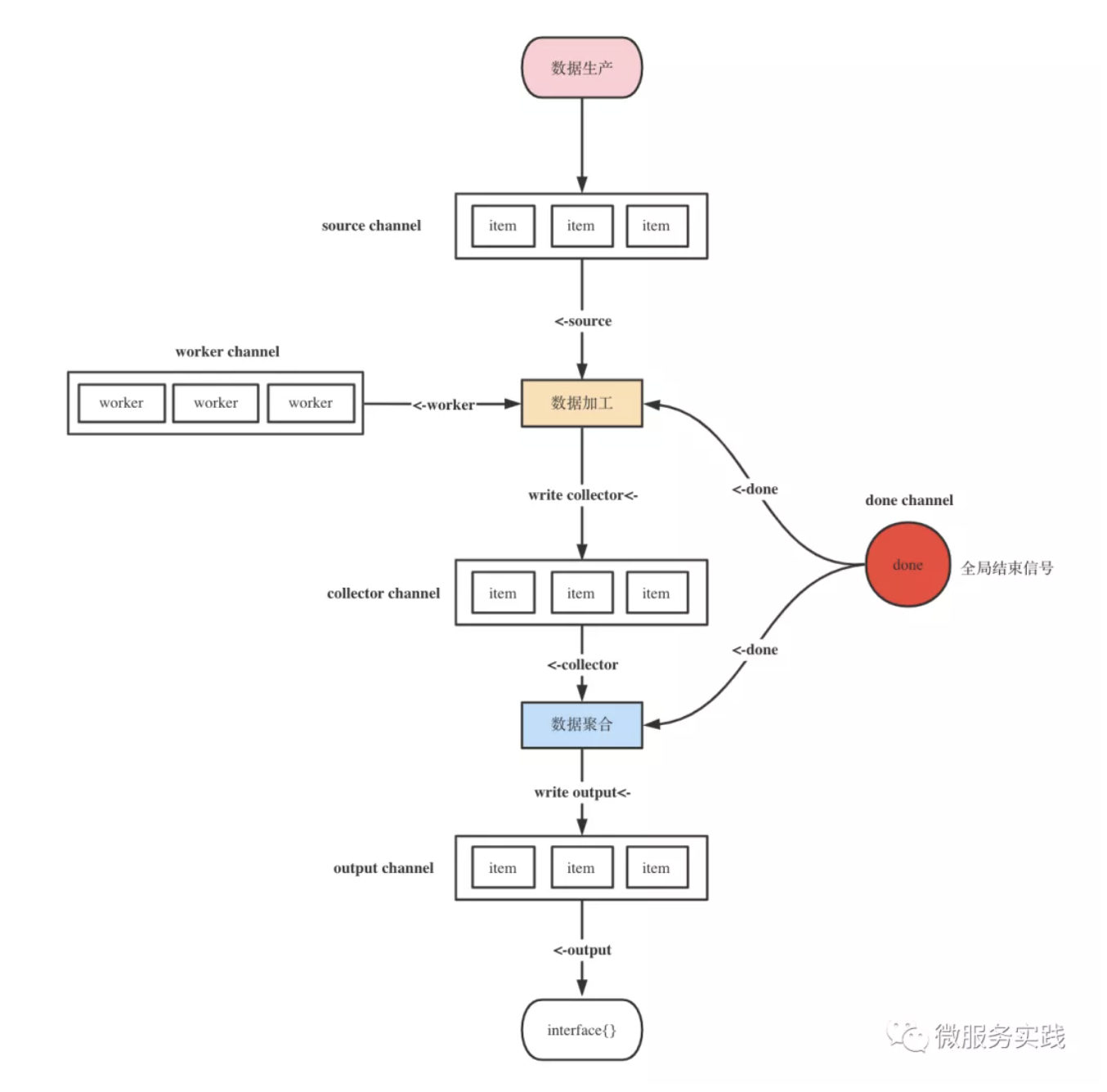
func MapReduceWithSource(source <-chan interface{}, mapper MapperFunc, reducer ReducerFunc,
opts ...Option) (interface{}, error) {
options := buildOptions(opts...)
output := make(chan interface{})
defer func() {
for range output {
panic("more than one element written in reducer")
}
}()
collector := make(chan interface{}, options.workers)
done := syncx.NewDoneChan()
writer := newGuardedWriter(output, done.Done())
var closeOnce sync.Once
var retErr errorx.AtomicError
finish := func() {
closeOnce.Do(func() {
done.Close()
close(output)
})
}
cancel := once(func(err error) {
if err != nil {
retErr.Set(err)
} else {
retErr.Set(ErrCancelWithNil)
}
drain(source)
finish()
})
go func() {
defer func() {
drain(collector)
if r := recover(); r != nil {
cancel(fmt.Errorf("%v", r))
} else {
finish()
}
}()
reducer(collector, writer, cancel)
}()
go executeMappers(func(item interface{}, w Writer) {
mapper(item, w, cancel)
}, source, collector, done.Done(), options.workers)
value, ok := <-output
if err := retErr.Load(); err != nil {
return nil, err
} else if ok {
return value, nil
} else {
return nil, ErrReduceNoOutput
}
}
func executeMappers(mapper MapFunc, input <-chan interface{}, collector chan<- interface{},
done <-chan lang.PlaceholderType, workers int) {
var wg sync.WaitGroup
defer func() {
wg.Wait()
close(collector)
}()
pool := make(chan lang.PlaceholderType, workers)
writer := newGuardedWriter(collector, done)
for {
select {
case <-done:
return
case pool <- lang.Placeholder:
item, ok := <-input
if !ok {
<-pool
return
}
wg.Add(1)
threading.GoSafe(func() {
defer func() {
wg.Done()
<-pool
}()
mapper(item, writer)
})
}
}
}
Usage examples
package main
import (
"log"
"time"
"github.com/tal-tech/go-zero/core/mr"
"github.com/tal-tech/go-zero/core/timex"
)
type user struct{}
func (u *user) User(uid int64) (interface{}, error) {
time.Sleep(time.Millisecond * 30)
return nil, nil
}
type store struct{}
func (s *store) Store(pid int64) (interface{}, error) {
time.Sleep(time.Millisecond * 50)
return nil, nil
}
type order struct{}
func (o *order) Order(pid int64) (interface{}, error) {
time.Sleep(time.Millisecond * 40)
return nil, nil
}
var (
userRpc user
storeRpc store
orderRpc order
)
func main() {
start := timex.Now()
_, err := productDetail(123, 345)
if err != nil {
log.Printf("product detail error: %v", err)
return
}
log.Printf("productDetail time: %v", timex.Since(start))
// the data processing
res, err := checkLegal([]int64{1, 2, 3})
if err != nil {
log.Printf("check error: %v", err)
return
}
log.Printf("check res: %v", res)
}
type ProductDetail struct {
User interface{}
Store interface{}
Order interface{}
}
func productDetail(uid, pid int64) (*ProductDetail, error) {
var pd ProductDetail
err := mr.Finish(func() (err error) {
pd.User, err = userRpc.User(uid)
return
}, func() (err error) {
pd.Store, err = storeRpc.Store(pid)
return
}, func() (err error) {
pd.Order, err = orderRpc.Order(pid)
return
})
if err != nil {
return nil, err
}
return &pd, nil
}
func checkLegal(uids []int64) ([]int64, error) {
r, err := mr.MapReduce(func(source chan<- interface{}) {
for _, uid := range uids {
source <- uid
}
}, func(item interface{}, writer mr.Writer, cancel func(error)) {
uid := item.(int64)
ok, err := check(uid)
if err != nil {
cancel(err)
}
if ok {
writer.Write(uid)
}
}, func(pipe <-chan interface{}, writer mr.Writer, cancel func(error)) {
var uids []int64
for p := range pipe {
uids = append(uids, p.(int64))
}
writer.Write(uids)
})
if err != nil {
return nil, err
}
return r.([]int64), nil
}
func check(uid int64) (bool, error) {
// do something check user legal
time.Sleep(time.Millisecond * 20)
return true, nil
}